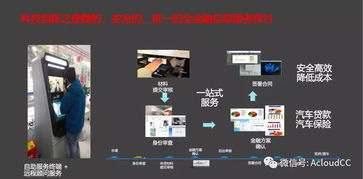
隨著人工智能(AI)技術的快速發展,其在企業營銷領域的應用日益廣泛。從智能化的客戶洞察到自動化的營銷執行,AI不僅提升了營銷效率,還為企業創造了前所未有的商業價值。本文將從人工智能在營銷中的具體服務方式出發,重點探討其如何通過公共服務和技術咨詢支持企業實現營銷創新。
一、人工智能在企業營銷中的核心應用
1. 個性化推薦與客戶體驗優化
AI通過分析用戶行為數據,能夠精準預測客戶偏好,實現個性化產品推薦。例如,電商平臺利用機器學習算法,為用戶提供定制化的購物建議,顯著提升轉化率。同時,AI驅動的聊天機器人和虛擬助手能夠提供24/7的客戶服務,增強用戶體驗。
2. 數據驅動的市場洞察
企業可以借助AI工具分析海量市場數據,識別潛在客戶群體和趨勢。自然語言處理(NLP)技術能夠從社交媒體、評論和調研報告中提取關鍵信息,幫助企業調整營銷策略,快速響應市場變化。
3. 自動化營銷流程
AI可以自動化執行重復性營銷任務,如郵件營銷、廣告投放和內容生成。通過預測分析,AI還能優化廣告預算分配,確保資源投入在最具潛力的渠道上。
二、人工智能公共服務的角色
人工智能公共服務平臺為企業提供了低門檻的AI工具和資源。例如,政府或行業協會主導的AI開放平臺可能提供數據共享、模型訓練和基礎算法服務。企業可以通過這些平臺快速接入AI能力,無需大量前期投資。公共服務還促進了行業標準制定和數據安全規范,幫助企業合規使用AI技術。
三、技術咨詢服務的價值
對于許多企業而言,內部缺乏AI專業知識是一大挑戰。專業的技術咨詢服務能夠填補這一空白。AI咨詢公司或專家團隊可以:
- 評估企業現有營銷流程,識別AI應用機會。
- 定制AI解決方案,如構建預測模型或集成智能工具。
- 提供培訓和持續支持,確保團隊能夠有效運用AI技術。
通過咨詢服務,企業可以避免技術選型錯誤,加速AI落地,并最大化投資回報。
四、成功案例與未來展望
以某零售企業為例,通過引入AI驅動的客戶分析系統,其營銷活動響應率提高了30%。同時,結合公共服務的數據資源和咨詢團隊的技術指導,該企業快速部署了智能廣告平臺,實現了營銷成本下降20%。
隨著AI技術的不斷成熟,其在企業營銷中的應用將更加深入。從增強現實(AR)互動營銷到基于生成式AI的內容創作,企業需要持續關注技術發展,并積極利用公共服務和咨詢服務,以保持競爭優勢。
結語
人工智能正重塑企業營銷的格局。通過充分利用公共服務資源并結合專業的技術咨詢,企業可以更高效、智能地觸達客戶,驅動業務增長。在AI時代,擁抱技術創新已成為企業營銷不可或缺的戰略選擇。